This content is directly taken from the blog post "The Case For Unidirectional Data Flow" by David Street
It’s no secret that more and more web applications are being driven by JavaScript; Both on the front-end as well as the back-end. As web applications become more complex, it becomes increasingly difficult to manage the state of an application, particularly on the front-end. Many libraries and frameworks exist to assist developers in creating these applications, but managing the interplay between data and application state is one of the most difficult challenges when developing and maintaining an application.
Recently, there have been a series of new frameworks introduced that promote the concept of unidirectional data flow. The most notable of which are React and Flux. React is an application view framework that utilizes a virtual DOM object to quickly render changes to an application state. Its counterpart, Flux, is an architecture to manage the flow of data, where interactions with the user interface trigger actions that in turn modify the application data and inform the view of any state changes.
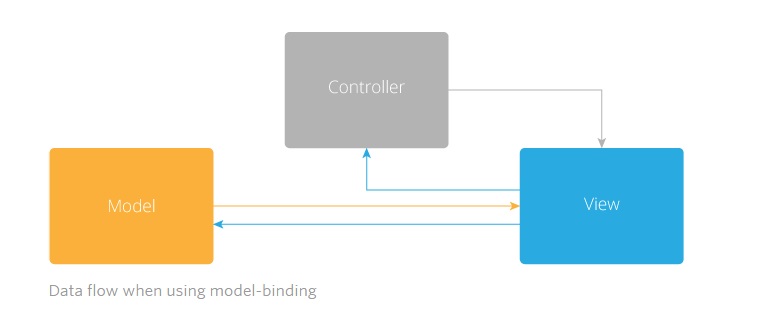
To fully understand the benefits of unidirectional data flow, you must first understand the inherent issues with the alternative. The alternative, of course, is bidirectional data flow. This data paradigm typically manifests itself as some sort of model binding. For many years, application architecture has revolved around the model-view-controller, or MVC, pattern. In this pattern, a model is responsible for storing and retrieving application data. The view is the presentation piece of the application–what the end-user sees. The controller is responsible for transforming data from a model so that it can be presented via the view.

For a long time, this pattern was exactly what we as developers needed. It offered separation of concerns. The view shouldn’t be concerned with where the data came from, and vice versa. The model shouldn’t concern itself with how the data is presented. This pattern works great for simple applications, but quickly starts to break down as applications become more complex. Many applications rely on user interaction to drive data and application state, which puts greater responsibility on the controller. It has to both maintain application state, and act as a mediator between the view and model. This complexity led us to model-binding, which allowed developers to auto-bind user interface changes to changes in the data model, and vice versa. Herein lies the problem: Application data and state are being manipulated from two sources and more or less bypassing the controller. The current state of the application is no longer predictable.
Unidirectional data flow, on the other hand, provides predictable application state. In a typical unidirectional application architecture, changes in an application view layer trigger an action within the data layer. Those changes are then propagated back to the view. It is important to note here that the view does not directly affect the application data.
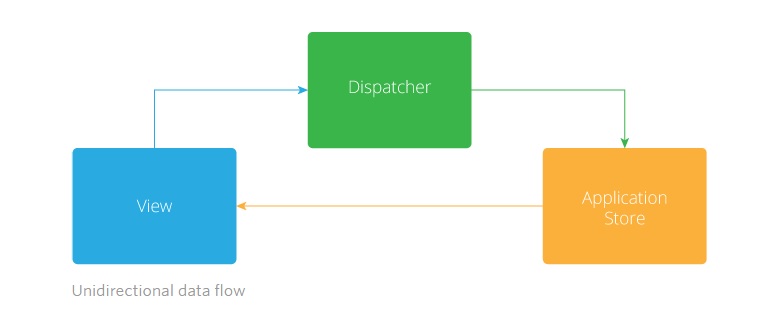
With frameworks like React, the view is simply a function of the application data. By function, I mean the mathematical sense of the word, where given the same set of inputs, the function will generate the same output. This is typically called a pure function, and is an excellent means for achieving unidirectional data flow, with predictable application state. A pure function only operates on a given set of inputs, must return a value, and does not produce any side effects. While pure functions are not the only means for achieving a unidirectional data flow, they can be the easiest to reason about and much easier to test against. The lack of side effects addresses the largest problem with a bidirectional flow of data–multiple points of failure.
By implementing an application architecture that allows data to only flow in one direction, you create more predictable application states. Should a bug become known in your application, a unidirectional data flow will make it much easier to pinpoint where the error lies, as data follows a strict pipeline. Through the use of pure functions, views are only loosely coupled to the application data allowing for greater flexibility and increasing maintainability.